
Data Storage Systems

Continuing with our discussion on storage with respect to Data Engineering. If you have not read the first post about Raw Ingredients of data, I would advise you that you first read that here.
Today we are going to look at Level 2: Data Storage Systems and all that it entails.
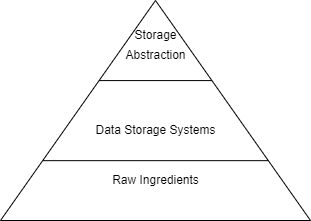
Level 2 of storage deals with storage systems. These systems exist as a level of abstraction over the Raw Ingredients level. Take for example magnetic disks and SSDs are part of raw ingredients but they are utilized in cloud object storage systems. We also have a higher level of abstraction such as Data Lake, Data Lakehouse, etc. We will discuss those in the Storage abstraction layer later. Let’s talk about different types of Data storage systems that we find in use currently.
Single Machine versus Distributed Storage: As data storage and access controls become complex they outgrow the usefulness of a single server distributing data to more than one server becomes necessary. Data can be stored in multiple servers, and coordination is set up across the servers to store, retrieve, and process the data faster and at a scale not possible in a single server storage. All of this is done while providing data redundancy so that in the event of a server crashing other servers can handle the work. Distributed storage is commonly used for systems where we want built-in redundancy and scalability for large data. It is used in Apache Spark, object storage, and cloud data warehouse. Consistency is an important factor to consider when using distributed storage.
? - Quobyte")
Eventual versus Strong Consistency: A major challenge faced by distributed storage is that since the data is spread across multiple servers it becomes increasingly difficult to keep the data consistent. Unlike most RDBMS implementing consistency takes time in distributed storage. Since we have multiple replications of data it takes time to make the appropriate change to all the servers where the data is located. This can amount to two users getting different data if they are located in different geographies. We have two common types of consistency patterns in distributed systems: eventual and string. We have covered ACID compliance before, now we are going to discuss BASE. BASE stands for Basically available, soft-state, eventual consistency. Let’s explore BASE some more.
Basically Available: It means that consistency is not guaranteed but consistent data is available most of the time. Database reads and writes are made on a best-effort basis.
Soft state: The state of the transaction is fuzzy, and it's uncertain whether the transaction is committed or uncommitted.
Eventual consistency: At some point, reading data will return consistent values.
Now you might think reading data from an eventual consistency is unreliable, so why use it? It is a trade-off which is commonly made for large-scale distributed systems. Eventual consistency allows you to retrieve data quickly without verifying that you have the latest version across all nodes. When we can’t tolerate query latency and we care about faster data reads and not data consistency then we use eventual consistency. There are some examples where we can’t compromise on consistency, and we always need the correct data then we make use of strong consistency but with query latency. Banks usually prefer strong consistency. Choosing eventual or strong consistency depends on both organizational problems and technology requirements. Data engineers should first gather all the requirements from all the stakeholders and choose the technologies appropriately.

File Storage: Files have become so common that it has become difficult to define them, but we will still do it here. A file is any data which has specific read, write and reference characteristics which are used by software and operating systems. Object storage behaves much like file storage but with a few key differences. File storage systems organize files into a directory tree. The file system stores each directory as metadata about the files and directories it contains. This metadata contains the name of each entity, relevant permissions details, and a pointer to the actual entity. To find a file on disk, the operating system looks at the metadata at each hierarchy level and follows the pointer to the next subdirectory entity until finally reaching the file itself. Some types of file storage systems can be seen below:
Local disk storage: This is the most familiar type of file storage. It is managed by the operating system on a local disk partition of SSDs or HDDs. Local file systems generally support full read-after-write consistency. Operating systems also employ various locking strategies to manage concurrent writing attempts to a file.

Image courtesy - datacore.com Network-attached storage (NAS): It provides a file storage system over a network. It is mostly used in servers where a company's LAN is used to store files in a central server and any system which has access and is connected to the local network can access those files. While there might be performance issues accessing a file over a network we get various benefits like huge storage capacity, reduced file redundancy when used across multiple people, and sharing large files across multiple machines.

? | StarWind Blog")
Cloud filesystem services: It provides fully managed filesystems for use with multiple cloud VMs and applications. Cloud filesystem services should not be confused with standard storage attached to VMs. Cloud filesystem services work like NAS but over VMs’. The operating tasks and configurations are all handled by the cloud service provider. Amazon’s Elastic file system (EFS) is an extremely popular example of cloud filesystem service. EFS provides automatic scaling and pay-per-storage pricing.
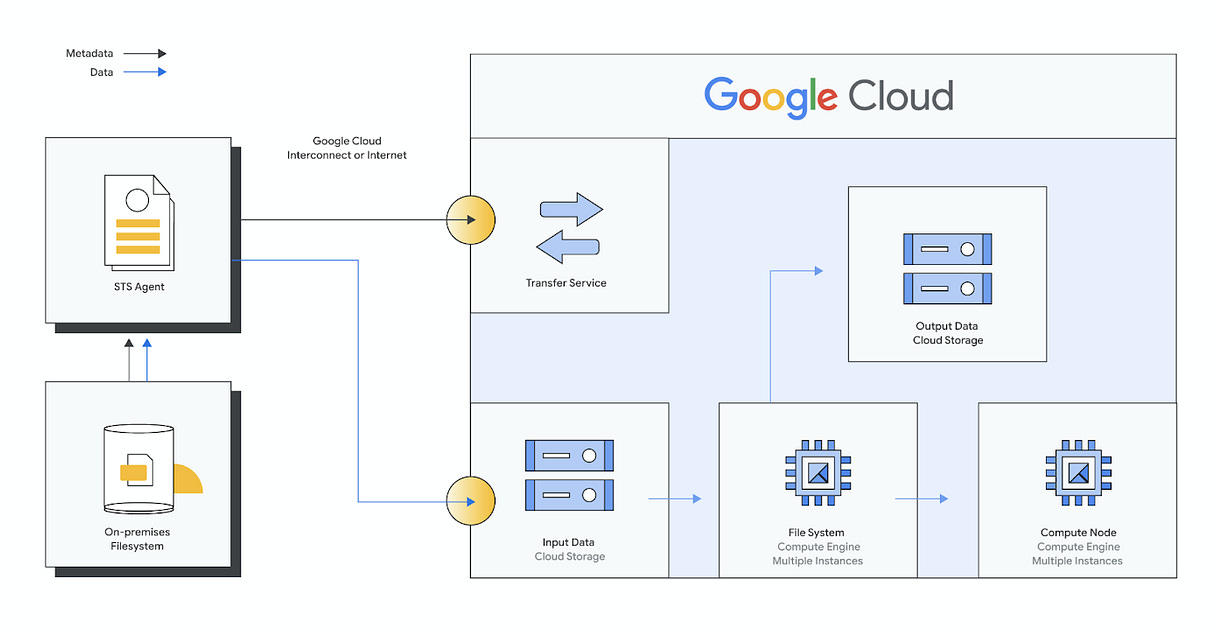
Block Storage: Fundamentally block storage is the type of raw storage provided by magnetic disks and SSDs. In the cloud, block storage has become a standard for VMs. A block is the smallest addressable unit of data supported by a disk. This used to be 512 bytes of usable data on older disks but now it has grown to 4,096 bytes for most current disks reducing the overhead of managing blocks. Blocks typically contain extra bits for error detection/correction and to store metadata.
Blocks on magnetic disks are geometrically arranged on a physical platter. Two blocks on the same track can be read without moving the head while reading two blocks on separate tracks requires a seek time. Seek time can also occur between blocks in SSDs but it is very small compared to seek time in magnetic disks.

Block Storage Applications – Transactional database systems generally access disks at a block level to lay out data for optimal performance. For row-oriented databases, the rows of data were written as continuous streams but with the advent of SSDs and the seek time associated with them, things have become complicated.
RAID – RAID stands for “Redundant array of independent disks”. RAID simultaneously controls multiple disks to improve data durability, enhance performance and combine capacity from multiple drives. Because of RAID capability, an array can appear to the operating system as a single block device. Many encoding and parity schemes are available to be used depending on the situation.
Storage Area Network (SAN)- These systems provide virtualized block storage over a network usually from a storage pool. SAN abstraction allows for fine-grained storage scaling, performance enhancement, availability, and durability.
Cloud virtualized block storage – They are just like SAN but since they are hosted and managed by cloud providers it frees the engineer from dealing with SAN clusters and networking details. Amazon Elastic Block Storage (EBS) is a standard example of it. EBS is used as the default storage for Amazon EC2 virtual machines.
Local instance volumes – Cloud service providers also provide block storage volumes that are physically attached to the host server on which the virtual machine runs. These are low-cost storage volumes that provide low latency and high IOPS (input-output operations per second). These storage volumes are essentially physical disks attached to a server in a data centre. One key defining feature of it is that once the power is shut down all the data in these local instance volumes are lost so they basically act as extra RAM.
Object Storage: By object, we mean specialized file formats like TXT, JSON, CSV, images, videos, audio, etc. Object storage contains objects of all shapes and sizes. Amazon S3 or Azure Blob storage are some common examples of Object storage. With the rise of big data and cloud object storage has become immensely important and popular. Many cloud data warehouses and some databases also utilize object storage as their storage layer and most cloud data lakes generally sit on object storage.
An object store is a key-value store for immutable data objects. We cannot change data in an object or append data to it, we must rewrite the full object. Object stores allow for random reads through range requests but the performance of these reads will be very bad compared to reads from data stored on an SSD. Software developers can leverage the parallel stream writes and reads capability of object storage without having to worry about how it works as it is all handled by the service providers. Typically object stores save data in several availability zones, dramatically reducing the odds that storage will go fully offline or be lost in an unrecoverable way. All of these features are part of the services that cloud service providers provide with their object storage.
Cloud object storage is a key ingredient in separating compute and storage. This allows engineers to process data for a short period and scale it up and down depending on the data or compute requirements. This helps save a lot of costs for the company. This feature has allowed smaller companies to delve into big data as they no longer need to own the hardware for data, they can just spin up an ephemeral cluster and run their process. Once their process is over they can easily close the cluster thereby saving a lot of money. Although some large companies will continue to run permanent Hadoop clusters on their hardware, the general trend is that most companies will migrate to cloud object storage for their processing needs.
Cache and Memory based storage systems: As discussed earlier RAM offers excellent latency and transfer speeds. However, most traditional RAMs are extremely volatile in nature. A power cut of even the smallest time can erase all the data contained in it. Ram-based storage systems are generally used for caching application data for quick presentation and access with high bandwidth and low latency. Memcached is a key-value store designed for caching database query results, API responses, and more. Memcached uses simple data structures like integers and strings to store data and deliver the results with very low latency and no load to the backend systems. Like Memcached, Redis is a key-value store but it supports more complex data types such as lists or tuples. Redis also has built-in persistence mechanisms, including snapshotting and journaling. Redis is suitable for extremely high-performance applications which can tolerate a small amount of data loss.

Hadoop Distributed File System: Not too long ago, Hadoop was considered big data. 9 times out of 10 if someone was talking about big data they meant Hadoop. Hadoop is based on Google File System (GFS) and it was initially made to process data using the MapReduce programming model. Hadoop is very similar to object storage with a key difference in that Hadoop combines the compute and storage in the same node.
Hadoop breaks down large files into small chunks of data usually smaller than a few hundred megabytes in size. The filesystem is managed by the Namenode which maintains directories, metadata, and a detailed catalog describing the location of the file blocks in the cluster. In the default configuration, each block of data is replicated 3 times across different nodes to increase the durability and availability of the data. If a disk or node fails the Namenode will instruct other nodes the replicate the file blocks on those nodes to reach the correct replication factor. Due to this, the probability of losing data in Hadoop is very low until and unless something huge occurs. Hadoop is not only a storage system but also a computing resource with storage nodes to allow in-place data processing.

You will often come across people saying that Hadoop is dead! That is only partially true. Although Hadoop is no longer a bleeding-edge technology and many Hadoop ecosystem tools such as Apache Pig are almost out of use, HDFS continues to be widely used even now. The fall of Hadoop can be attributed to MapReduce programming. Writing a MapReduce program is extremely difficult. Developers had a hard time developing efficient codes and soon companies realized that. Many large organizations still continue to use Hadoop in their legacy applications with no plan to migrate to newer technologies. This makes sense when companies have already invested a lot in setting up the infrastructure to run massive Hadoop clusters and they have the resources to maintain this system. For smaller companies, it makes sense to migrate to newer technologies as it considerably reduces the overhead cost. Although Hadoop might be fading out HDFS is here to stay as many new-age big data engines continue to use HDFS clusters. In fact, Apache Spark still commonly runs on HDFS clusters.
Streaming Storage: Streaming data has different requirements than non-streaming data. In the case of message queues, the data is temporary and is deleted after a fixed amount of time. However, modern distributed systems allow for longer retention of streaming data. Apache Kafka allows for indefinite storage of data by pushing old infrequently accessed data to object storage. Amazon Kinesis, Apache Pulsar and Google Cloud Pub/Sub also support longer retention of data.

Indexes, Partitioning and Clustering: Indexes are like maps of a table which follows a particular field. It allows for extremely fast data lookup. Without indexes, a database would need to scan an entire table to find the records. Index can be made for either a single field or multiple fields. Using indexes an RDBMS can loop up and update thousands of rows per second.

With the growing popularity of massive parallel processing (MPP) systems, there has been a shift towards parallel processing for significant improvements in scans across large quantities of data for analytics. Row-oriented databases did not perform well in these scenarios. This led to a rise in columnar databases. They perform poorly in transactional use, but they are extremely fast in scanning very large quantities of data to perform complex data transformations, aggregations, statistical calculations, etc. Earlier columnar databases performed poorly on joins but with the improvement in technology, their performance has dramatically improved.
While columnar databases allow for fast scans it still helps to reduce the amount of data to be scanned. In comes partition. Partition simply means dividing the table into multiple sub-tables by splitting it on a field. Since columnar databases are commonly used for analytics and data science use which does a lot of time range scan it makes sense to partition the data based on date and time.
Clusters allow finer-grained organization of data within partitions. A clustering scheme in a columnar database sorts data by one or more fields, collocating similar values. This helps in filtering, sorting, and joining performance.
A recent example of partitioning is Snowflake micro-partitioning where Snowflake partitions data into sets of rows between 50 and 500 megabytes in uncompressed size. Snowflake uses an algorithmic approach to cluster together similar rows.

Data Storage systems have been the go-to system for most people when it comes to using storage. Even without realizing we have been using these systems in our daily lives. There are some advanced data storage systems with very specific use cases but it’s safe to say that these storage systems have become pretty common. Adding an abstraction layer over the Raw ingredients has helped us increase capacity, improve performance and store data like never before. It gives us an easy medium to access data and also makes it easy to process it.
There is another level of storage called the Storage Abstraction. We can consider it as an abstraction over the Data Storage systems. This layer has very specific uses and is not usually used by common people. We will talk more about this abstraction layer in the next blog.
Thank you for joining us in this exploration of Data Storage Systems.
Happy learning
Ajay Mahato
This post was inspired by the book Fundamentals of Data Engineering by Joe Reis and Matt Housley.
As always, I would love to hear your thoughts and feedback on this post and how I can improve it further.
If you enjoyed this post, then you might be interested in some of my other posts.
Storage

This is part 1 of a multi-part series where we talk about storage with respect to Data engineering. Storage is the basis for any data engineering lifecycle. It is involved in three major parts of the Data Engineering lifecycle Ingestion, Transformation and Serving. Every data has to persist in storage until systems are ready to consume it or transmit it…
Message Queues and Event Streaming Platforms

With the rapid technology change, two important concepts Message Queues and Event Streaming Platforms stand out as key components of efficient communication and data flow. These technologies play a pivotal role in seamless communication between distributed technologies. While initially appearing as distinct technologies to those unfamiliar, message queu…